
By Naomi Meyer ’27
I began my work as a Collections Intern at the Mead a little over a year ago, in March of 2024, joining an ongoing project to enhance accessibility and searchability of artwork and cultural material spanning time periods, geographical areas, and mediums.
I was one of five other student interns, whose main task was to visually document stained glass panels in the windows of the Rotherwas Room (Fig. 1). While the room itself is a 17th-century room imported from an English castle, the thirty small stained glass panels adorning its windows were permanently installed to the current location at Amherst College when the museum was built in 1949. The scenes range from coats of arms to depictions of biblical tales and naval battles.
For each stained glass panel, we composed a detailed 150-word visual description. These texts had to be as objective as possible, omitting interpretations or analysis of any kind on our part. The initial purpose of these Visual Descriptions (VD) was to increase accessibility for visually impaired visitors. Often, I would also serve as editor of these VDs, ensuring that they were polished and presentable. Once each VDs was finished, whoever wrote the text would also record it. Both the visual and audio descriptions would be uploaded to the Mead’s online collections database.
While we had to remain objective while writing VDs, they required a specific kind of rigor. We had to ensure we were including significant details, while still accurately portraying the ‘big picture.’ We often did extensive research or referred to specific terminology lists when discussing parts of ships, aspects of medieval coats of arms, or historical and religious figures. We even brought in outside help, whether from professors or scholars who had expertise on various subject matters, or for translations and the appropriate use of non-English terms. Another challenge was to keep the word count to maximum 150 words, no matter how large or detailed the piece. By the end of the 2024 spring semester, the stained glass panels were finally done.

Fig. 1 Spring 2024 Mead Collections Interns Team in a digitally rendered image of the stained glass panels in the Rotherwas Room
When I resumed my internship in fall 2024, this time as one of only two collections interns, my work responsibilities in the collection accessibility project expanded beyond creating, editing, and translating VD (Fig. 2). It included tasks ranging from reaching out to peer institutions to gain insight into their accessibility projects, researching and updating our Visual Descriptions writing guidelines, planning and running events, but also tagging objects directly in the museum database.

Fig. 2 An example of a collection object (AC 2004.253) with visual and audio descriptions.
Throughout the academic year, my main focus remained on VD. I worked on specific groups of objects, as they were curated for classes in the museum’s study room, or, most commonly, for current or upcoming exhibitions. I did some work on objects for the spring semester iteration of “Part of an Impossible Task: Michael Rakowitz” exhibition, and I especially spent a lot of time on the Mead’s “Re/Presenting: Art Beyond the Color Line” exhibition, first concurrently with its first iteration from November to March, and then before its second iteration which went up in March and continues until July 6, 2025.
This was such a privilege because, since many of the objects were only recently acquired and did not yet have images uploaded to the database for me to work from, I was able to see the objects in person in the galleries. I even had the opportunity to handle some of the objects themselves. I was asked to work on Emma Nishimura’s photogravure sculptural bundles before they were on exhibition, and because they were three-dimensional, I was given the opportunity to carefully handle and examine them myself in order to compose as accurate and detailed a description as possible.
In addition to continuing to compose these descriptions myself, we began experimenting with Generative Artificial Intelligence (GenAI) to expedite the process of generating these texts (Fig. 3). Because I was the only intern, we wanted to find a way for me to oversee far more descriptions being created, rather than painstakingly writing them myself and it taking much longer. We looked into generative AI chatbots, ChatGPT and Claude.AI, and ultimately decided on the latter which described images in its free Claude Sonnet 4.7 version.

Fig. 3 Naomi Meyer ‘27’s workspace in the Mead’s William Green Study Room, editing Visual Descriptions and preparing for “Voice Your Belonging” April 17th event.
I began developing prompts for Claude, which I would then upload along with an image of the artwork on-line. Once the chatbot generated a description, I would read it and flag any issues, and rather than editing them myself, I would feed Claude more specific prompts to guide it into self-editing its own descriptions. Although I experimented a little with the initial prompt, I ended up keeping it rather simple, since each image and subsequent description would come with its own specific issues, which I could then address. The initial prompt I settled on was “Objectively describe this image for a blind individual, in a maximum of 150 words.”
I then had a list of the prompts I would most commonly have to give Claude to edit its texts, adjusting for specific edits. These included “Don’t interpret, analyze, or discuss the specific technique”; “Give detailed descriptions of the colors, shapes, etc. Whatever you can tell just from looking at it”; and “You can refer to race or skin color, age, and gender.”
The first of these addressed the most common issue with Claude’s initial descriptions; despite my instruction of an objective description, the first response was almost always too analytical or interpretative in one way or another—whether that meant stylistic techniques, intention of the artist, or actual analyses of the meanings of the artworks. As a result, the description often didn’t spend enough time on the visual details of the works, which meant I had to simultaneously tell it to strike certain aspects while also instructing it to “Use the remaining words to go into more objective detail about the image.”
On the other hand, the AI seemed especially wary of making any sort of assumptions about identities such as skin color, age, and gender. While we, as objective describers, also make a point of avoiding assumptions, AI took this to the point where it would simply ignore important aspects of the artwork, which were in fact visible. For instance, Gordon Parks’ photographs of Bethune-Cookman College not only identify the race of their subjects, but rely on them for the point they are making. Other examples, such as Eugène Delacroix’s Juive d’Alger make clear the gender of its subjects and rely on them for a better understanding, as it features a Jewish bride and her Muslim attendant in the Morocco’s port city of Tangier.
Once I had a description that fulfilled the guidelines I’d provided, I would take that and make final edits to cut down wordiness or add details of my own. While I did continue to write descriptions fully on my own for a few of the most complex objects, I transitioned into using AI for almost every object, which made the process much faster and easier for me to oversee. There were still a few issues, such as when Claude told me that an ancient Assyrian sculptural relief fragment of a hand holding a flower ornament was giving a “thumbs-up” gesture, but overall, the process began to run pretty smoothly (Fig. 4).
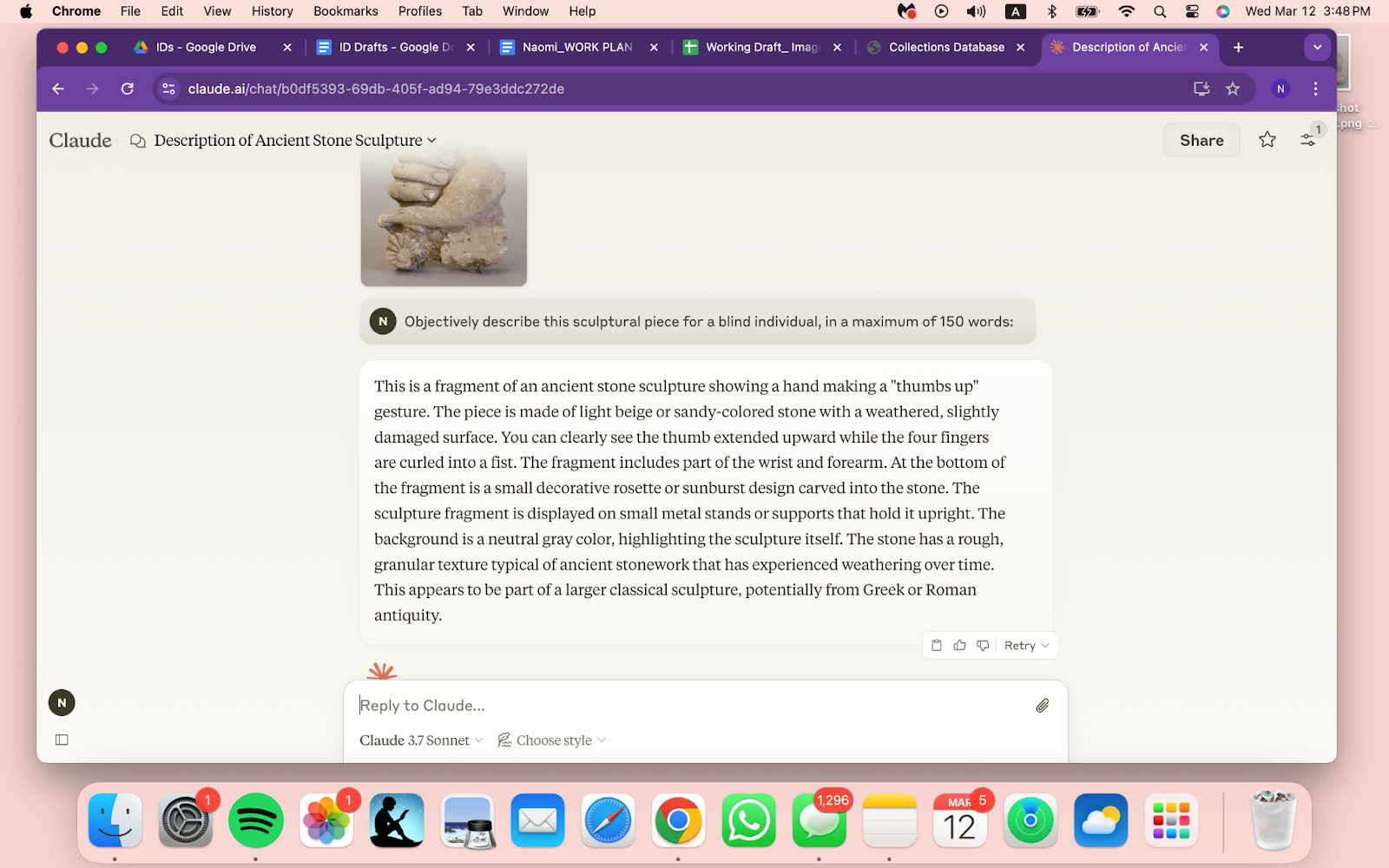
Fig. 4 Claude’s (Sonnet 4.7 version) description that an Assyrian sculptural relief fragment of a hand holding a flower ornament was giving a “thumbs-up”.
To test our efforts, share our enthusiasm, and engage a larger community in the project, we organized a public event “Voice Your Belonging, ” which we hosted during one of the museum’s late-night Thursdays in April. We invited visitors to record the descriptions Claude, the chatbot, and I had created. Amherst College students and faculty, Five-College undergraduates, and community members came and contributed their voices to the Mead’s online collection.
We brought the group to the galleries with the “Re/Presenting” exhibition, and began by providing participants with written descriptions without telling them which artwork they corresponded to. We then paired them up and had them sketch out what they envisioned based on their partner reading out the description provided to them. After, they had to use this description and their own sketches to walk through the galleries and find their artwork. To our delight, they all did!
We began with this exercise partly to make the evening even more fun, but also to test whether our descriptions really did their job of conveying the details of an artwork without having to actually see it. The drawings ended up going far beyond our expectations. Not only did they include all the same details as the actual artworks, but every single one resembled its corresponding artwork extremely closely, without the draftsperson having ever seen the artwork until after they sketched it (Fig. 5). The success of this event perfectly demonstrated the power and effectiveness of our visual descriptions in making art accessible to all.

Fig. 5 UMass Student Sophiya Iftikhar ‘27 holds her sketch up to Le Travail Interrompu, a painting by William-Adolphe Bouguereau (1891).
Naomi Meyer, class of 2027, is studying History, English, and International Relations at Amherst College. She is from Maryland, and has been a Collections Intern at the Mead since March, 2024. At Amherst, Naomi is a Tour Guide, Captain of Club Soccer, and on the Eboard of Mock Trial.

You must be logged in to post a comment.